
近年来得益于单细胞测序技术的发展,我们可以以单细胞分辨率去理解生物学过程,包括发育,衰老和疾病等。细胞类型注释在单细胞数据分析过程中非常关键,传统的注释方法是将细胞降维到去除批次效应的低维空间,再进行一轮或多轮不同分辨率的聚类,最后根据不同细胞簇的标记基因人工的标注细胞类型。这一过程缺乏公认的标准,很大程度上受到研究人员偏好的影响。此外,移除批次效应的同时保留生物学差异也是单细胞研究的难点。幸而,随着技术进步,越来越多大规模单细胞图谱产生并公开发表,为后续研究提供了重要参考,但同时也产生了开发能够高效处理大规模数据的计算工具的需求。所以,统一标准的,高效的,生物学可解释的细胞类型标注工具对于单细胞分析结果的可重复性和科学研究的持续发展至关重要。
近日,北京大学韩敬东课题组在 Nature Communications 期刊发表题为:Transformer for One Stop Interpretable Cell type Annotation 的研究论文。
该研究开创性的提出了基于多头自注意力机制的深度学习方法TOSICA,实现了无需任何批次信息输入,使用个人电脑,在数十分钟内对百万级单细胞数据的细胞类型注释,并建立多层次可解释性的,批次不敏感的,高分辨率的细胞低维表示。

与基于特征基因或相关性的机器学习方法相比,深度学习方法往往更适合处理大数据,更高效,更自动化。目前已经有大量基于自编码器(Autoencoder,AE)及其各种变体的细胞类型注释方法被开发,但受限于AE模型结构本身带来的弊端,此类方法大多伴随着特征提取过程中的信息损失,需要额外批次信息的辅助去除批次效应,以及无法在不牺牲模型深度或能力的情况下赋予隐空间生物学可解释性等问题。
Transformer是一种先进的,基于多头自注意力(Multi-head self-attention)机制的深度学习模型,拥有强大的全局信息集成能力和可解释性,它在自然语言处理(NLP)和计算机视觉(CV)等领域都取得了突破性进展。受这些优良特性的鼓舞,TOSICA 开创性的将Transformer计算单元运用到scRNA-seq数据分析领域。该模型首先将细胞中基因的表达信息转化成基因集特征(Gene set token)并添加一维用于分类的分类头(Class token),由于基因集间的离散特性,相对于传统Transformer模型,TOSICA无需位置信息编码(position embedding)而直接进入多头自注意力层进行特征集成,最后仅将class token接入分类器中得到细胞分类结果。
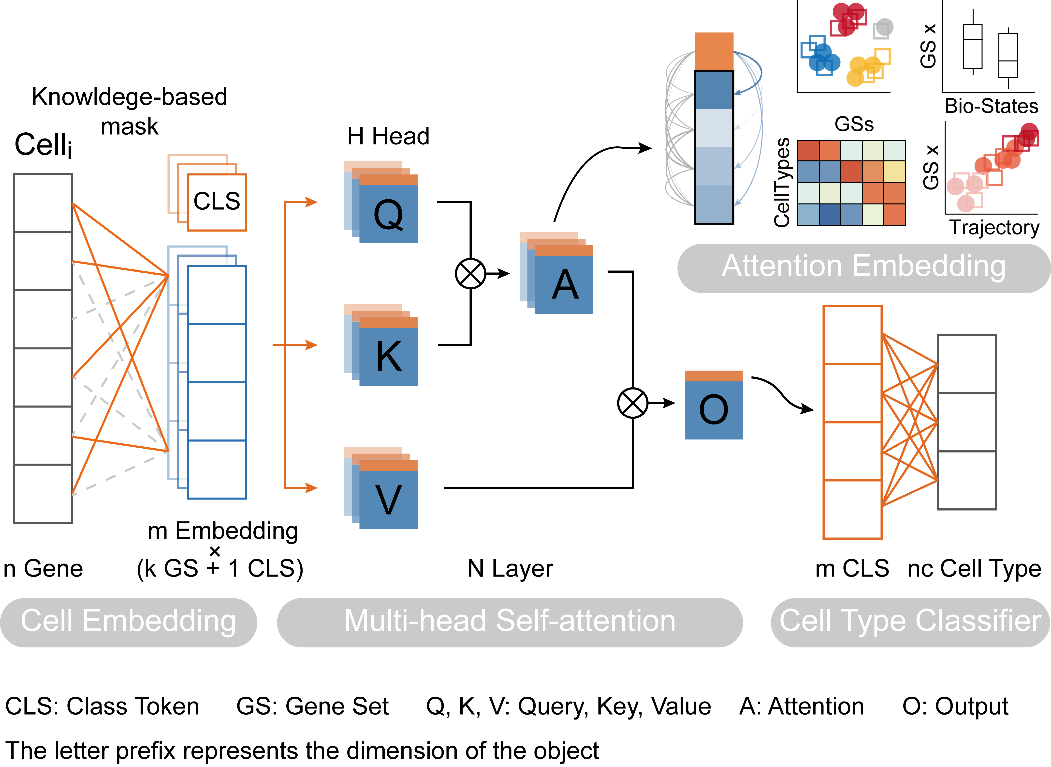
研究团队在多种不同的数据集中对模型的准确性进行了试验,包括疾病数据集,细胞类型不平衡数据集,发育数据集,复杂批次数据集,小鼠全组织图谱数据集。在横向比较的19种细胞类型注释器中,TOSICA综合准确性排名第一,运行时间随细胞数增加呈线性增加。值得注意的是,在规模大且细胞类型多的小鼠全组织图谱数据集和细胞类型不平衡数据集中,TOSICA的准确性分别领先第二名2%和6%。TOSICA还具有准确识别不同的新细胞类型,高灵敏鉴定过渡状态细胞,重构细胞动态轨迹,以及无需批次信息的批次效应去除等优秀特质。
随后研究团队在泛癌浸润T细胞数据集,泛癌浸润髓系细胞数据集,COVID19疾病数据集,红斑狼疮(SLE)数据集中验证了TOSICA在解决实际科学问题中的优势和潜力。实现了疾病相关可解释动态轨迹重构,鉴定随年龄,疾病状态,癌症类型变化而活化的通路,细分功能的细胞亚群鉴定,以及跨不同疾病模型的细胞类型迁移。



尊敬的 先生/女士
您已注册成功,注册信息及注意事项已发到联系人及参会人邮箱,请注意查收。如未收到,请联系大会联系人。
